Overview¶
HARK-Binaural+ includes binaural signal processing nodes for robot audition software HARK. You can also smoothly connect HARK-Binaural+ and other HARK packages such as HARK-FD or HARK-SSS packages.
Getting Started¶
- Add HARK repository and install Basic HARK Packages. See HARK installation instructions for details.
2. Install HARK-Binaural+
sudo apt-get install hark-binaural+
Binaural Signal Processing Nodes¶
This section describes following 5 signal processing nodes for binaural robot audition:
- BinauralMultisourceLocalization node
- BinauralMultisourceTracker node
- SourceSeparation node
- SpeechEnhanvement node
- VoiceActivityDetection node
BinauralMultisourceLocalization Node¶
Outline of the node¶
This node identify the location of sound sources in direction with two microphones.
Typical connection¶
The type of the input is multi-channel (2-ch) audio spectrum and that of the output is a list of localized directions of sound sources. Typical connection of this node is depicted as follows:
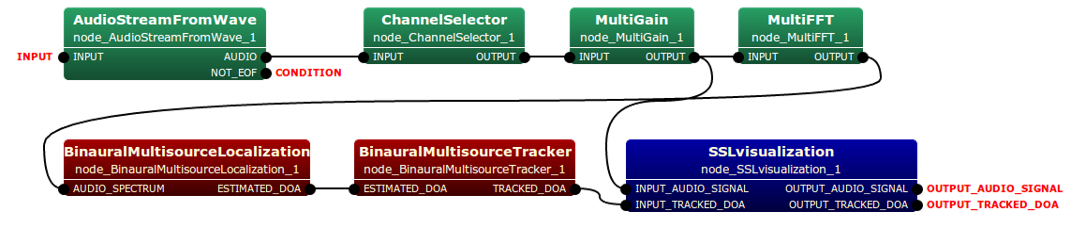
Input-output and property of the node¶
Input¶
- AUDIO_SPECTRUM Matrix<complex<float> >
- Windowed spectrum data. A row index is channel, and a column index is frequency.
Output¶
- ESTIMATED_DOA Matrix<complex<float> >
- Estimated directions of multi-sources.
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| SOUND_DIFFRACTION_COMPENSATION | string | FREE_SPACE | Compensation for the diffraction of sound waves with multi-path interference caused by contours of a spherical robot head. | |
| GCCPHAT_THRESHOLD | float | 0.25 | Threshold to avoid estimating DOAs of noise and reverberated sources. | |
| MICS_DISTANCE | float | 17.4 | cm | Distance between two microphone. |
| NOISE_DURATION | float | 1.0 | second | Time duration to be regarded as “noise” from the first frame. |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate. |
Detail of the node¶
This node localizes sound sources based on generalized cross-correlation method weighted by the phase transform (GCC-PHAT) [1]. Although the basic GCC-PHAT algorithm assumes the number of sound sources is one, we maintain multiple sound sources by using dynamic K-means clustering [2] that is implemented in BinauralMultisourceTracker node. The localization performance is improved by signal-to-noise ratio (SNR)-weighting [3].
Let \(\hat{\Theta}_{mel} = \{\hat{\theta}_1, \hat{\theta}_2, \hat{\theta}_3, \cdots\}\) be directions of sound sources localized, the binaural sound source localization is conducted following process:
\(\hat{\Theta}_{mel} = \mathop{\rm argmax}_{\theta} \frac{1}{F} \sum^F_{f=1} \frac{SNR_{inst}[f,n]}{1 + SNR_{inst}[f,n]} \cdot \frac{X_l[f,n]X_r^{\ast}[f,n]}{\left|X_l[f,n]X_r^{\ast}[f,n]\right|} \exp{\left( j2 \pi \frac{f}{F} fs \tau_{multi}(\theta) \right)},\)
\(SNR_{inst}\left[f,n\right]=\frac{\left|X_l\left[f,n\right]X_r^{\ast}\left[f,n\right]\right|-E\left[\left|N_l\left[f,n\right]N_r^{\ast}\left[f,n\right]\right|\right]} {E\left[\left|N_l\left[f,n\right]N_r^{\ast}\left[f,n\right]\right|\right]}\), and
\(\tau_{multi}(\theta)=\frac{d_{lr}}{2v} \left( \frac{\theta}{180}\pi + {\rm sin}\left( \frac{\theta}{180}\pi \right) \right) - \frac{d_{lr}}{2v}\left({\rm sgn}(\theta)\pi - \frac{2\theta}{180}\pi \right) \cdot \left|\beta_{multi} {\rm sin}\left( \frac{\theta}{180}\pi\right)\right|\)
where \(X\left[f, n\right]\) represents an input audio signal at frequency bin \(f\) and time frame \(n\).
References¶
| [1] |
|
| [2] |
|
| [3] |
|
BinauralMultisourceTracker Node¶
Outline of the node¶
This node tracks the sound source locations estimated by BinauralMultisourceTracker node.
Typical connection¶
See Typical connection of the BinauralMultisourceLocalization node. To maintain multiple sound sources, this node is connected from the BinauralMultisourceLocalization node, and clusters the output of the localization node based on dynamic K-means clustering
Input-output and property of the node¶
Input¶
- ESTIMATED_DOA Vector<ObjectRef>
- Estimated directions of multisource.
Output¶
- TRACKED_DOA
- Tracked directions of multisource.
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| CLUSTERING_DURATION | float | 0.25 | second | Time duration to cluster direction estimations. |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate. |
SourceSeparation Node¶
Outline of the node¶
This node conducts blind sound source separation based on independent vector analysis.
Typical connection¶
The type of both the input and output of SourceSeparation node is multi-channel (2-ch) audio spectrum. Typical connection of this node is depicted as follows:
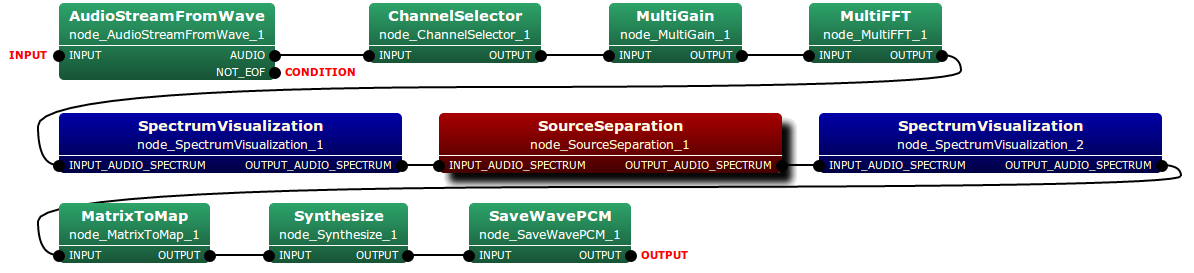
Input-output and property of the node¶
Input¶
- INPUT_AUDIO_SPECTRUM Matrix<complex<float> >
- Windowed spectrum data. A row index is channel, and a column index is frequency.
Output¶
- OUTPUT_AUDIO_SPECTRUM Matrix<complex<float> >
- Windowed and speech-enhanced spectrum data . A row index is channel, and a column index is frequency.
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| FFT_LENGTH | int | 512 | sample | Analysis frame length. |
| ITERATION_METHOD | string | FastIVA | Iteration method. | |
| MAX_ITERATION | int | 700 | Processing limitation: maximum number of iterations. | |
| NUMBER_OF_SOURCE_TO_BE_SEPARATED | int | 2 | Number of sound sources to be separated. | |
| SEPARATION_TIME_LENGTH | float | 5.0 | second | Separation window length. |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate. |
Details of the node¶
This module conducts recovery of the original sound signals from the combined sound signal by using independent vector analysis (IVA) [4] or Fast independent vector analysis (Fast-IVA) [5]. In the case of IVA, the objective function is Kullback-Leibler (KL) divergence:
\(C={\rm constant}- \sum^F_f {\rm log}\left|{\rm det} W_{mkf}\right| - \sum^M_m E\left[{\rm log}P \left( \hat{S}_1, \cdots ,\hat{S}_M \right)\right]\)
where \(\hat{S}_m (m = 1, \cdots, M)\) and \(W_{mkf}\) represent the input signal of m-th microphone and the separation matrix of IVA, respectively. The lerning algorithm of IVA is based on natural gradient-descent method:
\(W^{new}_{mkf}=W^{old}_{mkf} + \eta \sum^K_k \left( I_{mk} - E \left[ \frac{\hat{S}_{kf}}{\sqrt{\sum^F_f \left| \hat{S}_{kf} \right|^2}} \hat{S}_{kf}^{\ast} \right] \right) W^{old}_{mkf}\)
where \(\eta\) is learning rate (set at 0.1)
In the case of Fast-IVA, following modified objective function based KL divergence on is used:
\(C=-\sum^M_m E\left[{\rm log}P \left( \hat{S}_1, \cdots ,\hat{S}_M \right)\right] - \sum^M_m \beta\left[W^T_{mkf}W^{new}_{mkf}-1\right]\),
where \(\beta\) is Langrangian multiplier. The learning algorithm, on the other hand, is based on newton method with fixed point iteration:
\(W^{new}_{mkf}= E\left[\frac{1}{\sqrt{\sum^F_f \left|\hat{S}_{kf}\right|^2}} - \frac{\hat{S}^2_{kf}}{\left( \sqrt{\sum^F_f \left|\hat{S}_{kf}\right|^2}\right) ^3}\right] W^{old}_{mkf} -E\left[\frac{\hat{S}_{kf}}{\sqrt{\sum^F_f \left|\hat{S}_{kf}\right|^2}} X_{kf}\right]\)
References¶
| [4] |
|
| [5] |
|
SpeechEnhancement Node¶
Outline of the node¶
This node improves the quality of the sound signal including a speech degraded by noise.
Typical connection¶
The type of both the input and output of this node is multi-channel audio spectrum. Typical connection of this node is depicted as follows:
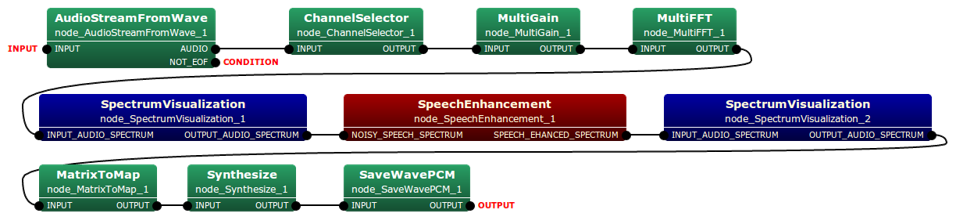
Input-output and property of the node¶
Input¶
- NOISY_SPEECH_SPECTRUM Matrix<complex<float> >
- Windowed spectrum data. A row index is channel, and a column index is frequency.
Output¶
- SPEECH_EHANCED_SPECTRUM Matrix<complex<float> >
- Windowed and speech-enhanced spectrum data . A row index is channel, and a column index is frequency.
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| NOISE_REDUCTION_METHOD | string | MINIMUM_MEAN_SQUARE_ERROR | Noise reduction methods | |
| HARMONIC_REGENERATION | string | USE | Harmonic regeneration after noise reduction | |
| NOISE_PERIOD | float | 1.0 | second | Time to be regarded as “noise” from the first frame. |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate |
Detail of the node¶
This module supports noise reduction and harmonic regeneration by conducting spectral subtruction [6], wiener filtering [7], minimum mean squre error (MMSE) [8], two step wiener filtering (TSNR), and harmonic regeneration (HRNN) methods [9]. Let \(X\left[f, n\right]\) be an input audio signal at frequency bin \(f\) and time frame \(n\), each method is conducted following processing.
Spectral subtraction: \(\hat{S}\left[f,n\right]=\left( \left|X\left[f,n\right]\right|^2 - \hat{\gamma}_N \right)\)
Wiener filtering: \(G_{Wiener}\left[f,n\right] = \hat{SNR}_{Decision-Directed}\left[f,n\right]/ \left( \hat{SNR}_{Decision-Directed}\left[f,n\right]+1 \right)\)
MMSE: \(G_{MMSE}\left[f,n\right] = gamma\left(1.5\right)\left(V_k\right)^{0.5} / \hat{SNR}_{instantaneous}\left[f,n\right]\cdot {\rm exp}(-V_k/2)\cdot (1+V_k) {\rm Bessel_0}\left(V_k /2\right) + V_k {\rm Bessel}_1\left(V_k /2\right)\),
where \(V_k = G_{Wiener}\left[n\right] \cdot \hat{SNR}_{instantaneous}\left[n\right]\)
TSNR: \(G_{TSNR}\left[f,n\right] = \hat{SNR}_{TSNR}\left[f,n\right]/ \left(\hat{SNR}_{TSNR}\left[f,n\right] + 1\right)\) , where \(\hat{SNR}_{TSNR}\left[f,n\right] = {\left|G_{Decision-Directed}\left[f,n\right] X\left[f,n\right]\right|}^2 / \hat{\gamma}_N\)
References¶
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
VoiceActivityDetection Node¶
Outline of the node¶
This node delimits the a speech-present period.
Typical connection¶
This node is connected with the VoiceActivityDetection node. Typical connection of this node is depicted as follows:
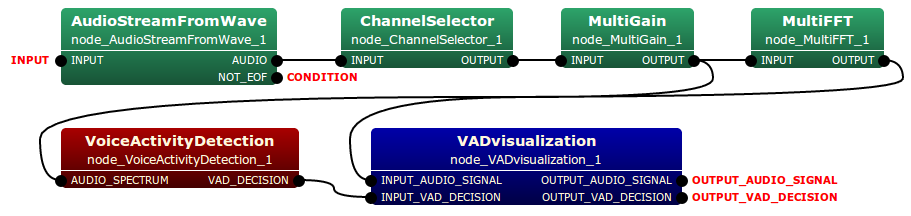
Input-output and property of the node¶
Input¶
- AUDIO_SPECTRUM Matrixd<complex<float> >
- Windowed spectrum data. A row index is channel, and a column index is frequency.
Output¶
- VAD_DECISION Vector<ObjectRef>
- Decision of speech-present frame
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| VAD_NOISE_DURATION | float | 3.0 | second | Time duration to be regarded as “noise” from the first frame |
| VAD_THRESHOLD | float | 50.0 | Threshold for voice activity decision. | |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate. |
Detail of the node¶
This node estimates the voice activity by using log likelifood ratio of speech and noise variances of the zero-mean Gaussian statistical model [10]. Let \(X_{l/r}\left[f, n\right]\) be an input audio signal at frequency bin \(f\) and time frame \(n\), this method regards speech-present when following equation is satisfied:
\(\frac{1}{F} \sum^{F}_{f=1} \gamma \left[f,n\right]- {\rm log} \gamma \left[f,n\right] -1 > \eta_{VAD}\),
\(\lambda_N \left[f\right] = E\left|N_l\left[f\right] \cdot N_r\left[f\right]^{\ast}\right|\),
\(\gamma\left[f,n\right]=\left|X_l \left[f,n\right] \cdot X_r\left[f,n\right]^{\ast}\right|/ \lambda_N\left[f\right]\),
where \(N\left[f\right]\) and \(\eta_{VAD}\) represent the variance of a estimated noise and threshold parameter, respectively.
Visualization Nodes¶
This section describes following 4 visualization nodes for the previous 5 nodes.
- SSLVisualization node
- SpectrumVisualization node
- VADVisualization node
- WaveVisualization node
SSLvisualization Node¶
Outline of the node¶
This node visualizes the estimated sound source locations.
Typical connection¶
See Typical connection of the BinauralMultisourceLocalization node. This node can be connected with BinauralMultisourceTracker node. The following figure shows an example of the visualization.
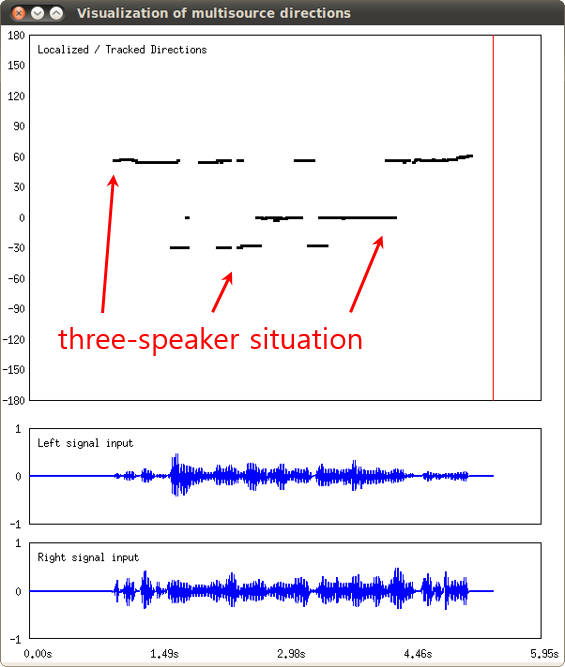
Input-output and property of the node¶
Input¶
- INPUT_AUDIO_SIGNAL any
- Input should be Matrix<float> or Map<int,ObjectRef>. In case of Matrix<float>, the rows should be channel indices and the columns should be frequency indices. In case of Map<int,ObjectRef>, the key is a source ID and the value is a vector of audio signals (Vector<float>).
- INPUT_TRACKED_DOA Vector<ObjectRef>
- Estimated/tracked directions of multisource.
Output¶
- OUTPUT_AUDIO_SIGNAL any
- Same as INPUT_AUDIO_SIGNAL
- OUTPUT_TRACKED_DOA Vector<ObjectRef>
- Same as INPUT_TRACKED_DOA
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| WINDOW_NAME | string | Visualization of multisource directions | Window name of the time-azimuth map. | |
| VISUALIZATION_TIME_LENGTH | float | 10.0 | second | Visualization window length to show at the same time. |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate. |
SpectrumVisualization Node¶
Outline of the node¶
This node visualizes the audio spectrum.
Typical connection¶
See Typical connection of the Source Separation node. Following figure shows the visualization result of spectrum on the input signal.
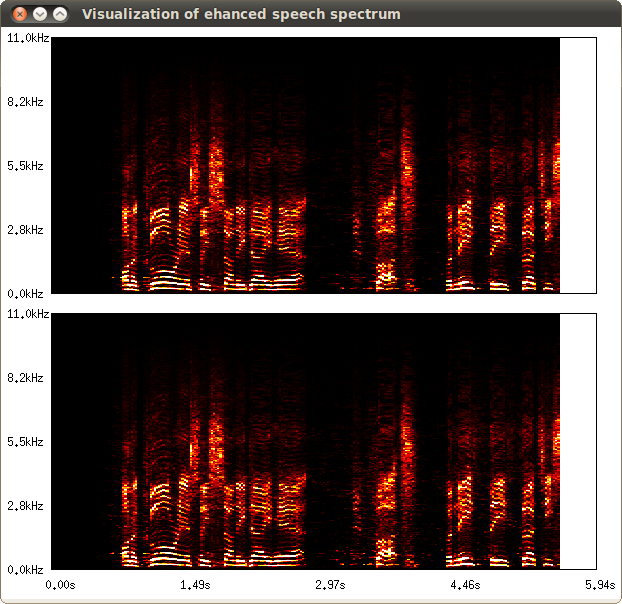
Input-output and property of the node¶
Input¶
- AUDIO_SPECTRUM Matrixd<complex<float> >
- Windowed spectrum data. A row index is channel, and a column index is frequency.
Output¶
- AUDIO_SPECTRUM Matrix<complex<float> >
- Same as INPUT_AUDIO_SIGNAL
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| WINDOW_NAME | string | Visualization of audio spectrum | Visualization of audio spectrum. | |
| VISUALIZATION_TIME_LENGTH | float | 10.0 | second | Visualization window length to show at the same time. |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate. |
VADvisualization Node¶
Outline of the node¶
This node visualizes the detected speech segments.
Typical connection¶
See Typical connection of the VoiceActivityDetection node. Following figure shows the visualization result of VAD overlayed on the input signal.
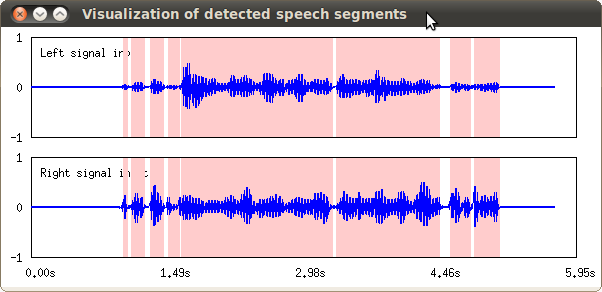
Input-output and property of the node¶
Input¶
- INPUT_AUDIO_SIGNAL Matrix<complex<float> >
- Input should be Matrix<float> of Map<int,ObjectRef>. In case of Matrix<float>, the rows should be channel indices and the columns should be frequency indices. In case of Map<int,ObjectRef>, the key is a source ID and the value is a vector of audio signals (Vector<float>).
- INPUT_VAD_DECISION Vector<ObjectRef>
- Decision of speech-present frame.
Output¶
- OUTPUT_AUDIO_SIGNAL any
- Same as OUTPUT_AUDIO_SIGNAL.
- OUTPUT_VAD_DECISION Vector<ObjectRef>
- Same as INPUT_VAD_DECISION.
Parameters¶
Parameters of this node are listed as follows:
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| WINDOW_NAME | string | Visualization of detected speech segments | Window name of the time-azimuth map. | |
| VISUALIZATION_TIME_LENGTH | float | 10.0 | second | Visualization window length to show at the same time. |
| ADVANCE | int | 160 | sample | The length in sample between a frame and a previous frame. |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate. |
WaveVisualization Node¶
Outline of the node¶
This node visualize the signal wave.
Typical connection¶
The type of both the input and output of SourceSeparation node is multi-channel (2-ch) audio spectrum. Typical connection of this node is depicted as follows:

The following figure shows the example of the result.
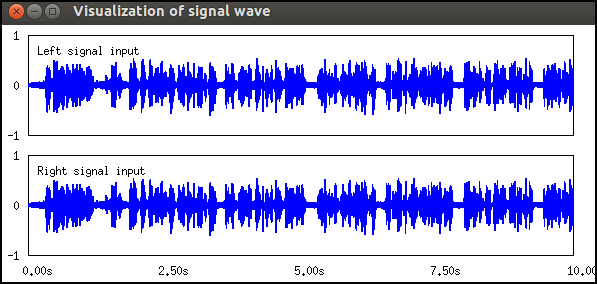
Input-output and property of the node¶
Input¶
- INPUT_AUDIO_SIGNAL any
- Input should be Matrix<float> or Map<int,ObjectRef>. In case of Matrix<float>, the rows should be channel indices and the columns should be frequency indices. In case of Map<int,ObjectRef>, the key is a source ID and the value is a vector of audio signals (Vector<float>).
Output¶
- OUTPUT_AUDIO_SIGNAL any
- Same as input.
Parameter list of
| Parameter name | Type | Default value | Unit | Description |
|---|---|---|---|---|
| WINDOW_NAME | string | Visualization of detected speech segments | Window name of the time-azimuth map | |
| VISUALIZATION_TIME_LENGTH | float | 10.0 | Visualization window length to show at the same time | |
| ADVANCE | int | 160 | The length in sample between a frame and a previous frame | |
| SAMPLING_RATE | int | 16000 | Hz | Sampling rate |