| HARK Cookbook |
| HARK Cookbook |
Problem
To describe a method for constructing language models for speech recognition.
Solution
Creation of a dictionary for Julius
Create a dictionary in the HTK format based on a morphologically-analyzed right text. Use chasen (bamboo tea whisk) for morphological analysis. Install chasen and create.chasenrc in the Home directory. Designate the directory having grammar.cha in it as a "grammar file" and describe the output format as
(grammar file /usr/local/chasen-2.02/dic)) (output format "%m+%y+%h/%t/%f\n"))
Prepare a right text file and call it seikai.txt. Since it is used for language model creation, insert 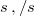 at the beginning and end of each sentence, respectively.
at the beginning and end of each sentence, respectively.
Example of seikai.txt (words do not need to be separated) <s> Twisted all reality towards themselves. </s> <s> Gather information in New York for about a week. </s>
% chasen seikai.txt > seikai.keitaiso
See the contents of text.keitaiso; if any part of the morphological analysis is incorrect, revise it. Moreover, since the notion and reading of "he" and "ha" differ, alter their reading to "e" and "wa", respectively. It may be necessary to normalize of morphemes and remove other unwanted parts. These steps are omitted here.
Example of seikai.keitaiso <s>+<s>+17/0/0 + +75/0/0 </s>+</s>+17/0/0 EOS++ <s>+<s>+17/0/0
% w2s.pl seikai.keitaiso > seikai-k.txt
+ +75/0/0 </s>
% dic.pl seikai.keitaiso kana2phone_rule.ipa | sort | uniq > HTKDIC % gzip HTKDIC
</s> [] silE <s> [] silB + +75/0/0 [] sp a r a y u r u
Termx Those included in morphological analysis, chasen, HTK format, w2s.pl, dic.pl and kana2phone_rule.ipa - vocab2htkdic
Creation of language model for Julius
For creation of a language model, see “Speech recognition system” (Ohm sha). To create 2-gram and reversed 3-gram such as jconf of samples, however, use of the CMU-Cambridge Toolkit alone is not sufficient, requiring the use of palmkit, which is compatible with CMU-Cambridge Toolkit. Moreover, the reversed 3-gram has become unnecessary for Julius; therefore, it may be not always necessary to use palmkit. To use palmkit, prepare a correct answer text, designating it seikai-k.txt. This file requires morphological analysis; i.e., punctuation is regarded as a word, with words separated by spaces.  and
and 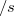 are inserted at the beginning and end of each sentence, respectively, remove transition over and . In this case, descriptions of and are required for the learn.css file.
are inserted at the beginning and end of each sentence, respectively, remove transition over and . In this case, descriptions of and are required for the learn.css file.
% text2wfreq < learn.txt > learn.wfreq % wfreq2vocab < learn.wfreq > learn.vocab % text2idngram -n 2 -vocab learn.vocab < learn.txt > learn.id2gram % text2idngram -vocab learn.vocab < learn.txt > learn.id3gram % reverseidngram learn.id3gram learn.revid3gram % idngram2lm -idngram learn.revid3gram -vocab learn.vocab -context learn.ccs % -arpa learn.rev3gram.arpa % idngram2lm -n 2 -idngram learn.id2gram -vocab learn.vocab -context learn.ccs % -arpa learn.2gram.arpa
The 2-gram and reversed 3-gram are created and all are collected. A language model for Julius is created with the tool mkbingram of Julius as follows
% mkbingram learn.2gram.arpa learn.rev3gram.arpa julius.bingram
See Also
| HARK Cookbook |